Fault Tolerance for Microservices

What is it, why you should care, and how to apply it using Quarkus.
While working on a cluster comprised of microservices, you will most likely find yourself retrieving information from external providers (web services residing outside of your cluster, for example). Or you may have spotted some cases where your microservices are struggling to cope with a substantial spike in network traffic and that this struggle is propagated across all of your microservices.
What you have identified such technical issues, it’s time to think about fault tolerance mechanics, and how to apply them correctly for your use case.
But what is Fault Tolerance?
According to Wikipedia:
Fault tolerance is the property that enables a system to continue operating properly in the event of the failure of (or one or more faults within) some of its components
When it comes to a Kubernetes cluster, Fault Tolerance is the appliance of certain practices in terms of deployments and code structure that will allow your Kubernetes cluster to recover from errors gracefully and without degrading the user experience.
In this article, we are going to set up a simple imaginary scenario to show where Fault Tolerance becomes essential. We are then going to examine how to apply Fault Tolerance in a key microservice using Quarkus and MicroProfile.
Quarkus is Red Hat’s new microservices-targeted framework, comprised of a large number of extensions that allow tackling with a plethora of development needs — from REST API calls to handling Security, Kafka Streams, and Fault Tolerance. Quarkus is 100% Microprofile Specification compliant.
An example scenario:
Consider the following simple architecture.
In the below schema, we have microservices A, B, and C. Microservice C communicates with an external provider to fetch data. Microservices A and B rely on C to retrieve information.
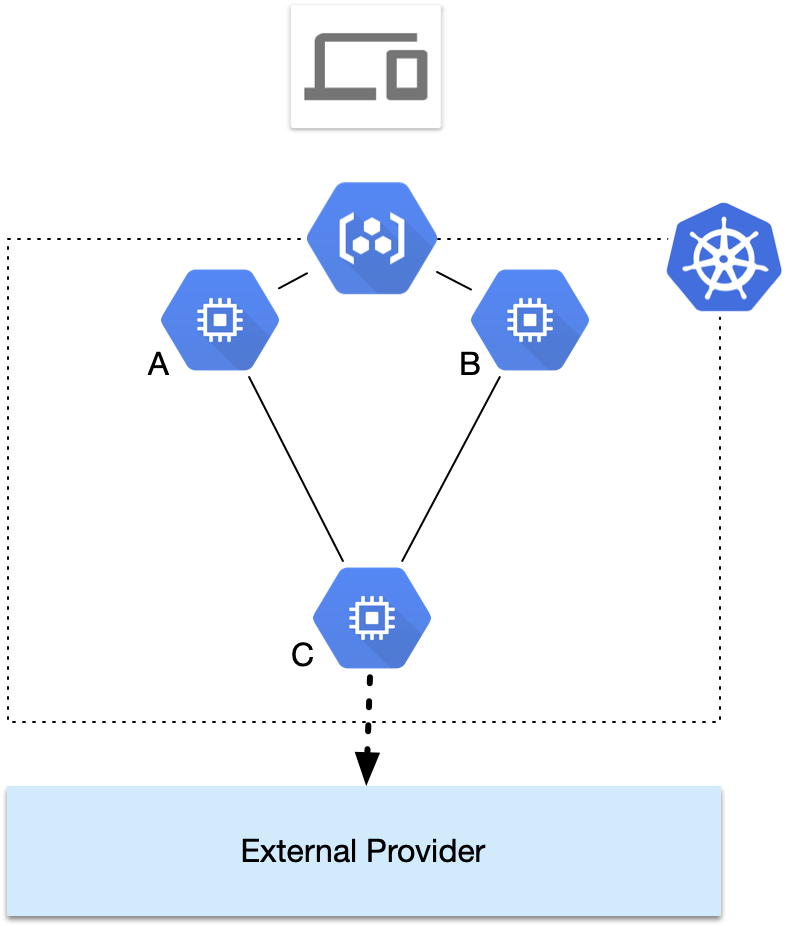
In a much larger deployment, A and B would aggregate information from many more sources — but for the sake of simplicity, we have narrowed the scope of our imaginary Kubernetes cluster to just those three microservices.
Let’s just imagine that the external provider is a system that sometimes takes too long to answer when too many requests are being made towards it. In that particular scenario, the microservices A and B will make HTTP requests towards microservice C. Each HTTP request is going to use one i/o thread (or create a new one if the thread pool is empty) and those threads will remain open until a response is received.
This means that while waiting for the HTTP response, all three microservices consume resources while waiting for a response from the External Provider.
Your users don’t know that, and as more of them make requests to your site / mobile app, even more threads are being created. As your microservices continue to create more threads, they consume both CPU and RAM to synchronize and maintain them. Threads are quickly pile up until they reach a certain threshold where your application needs more memory to sustain them. Garbage collection will eventually kick in when RAM consumption reaches dangerous levels, consuming even more CPU.
At this point, Kubernetes will try to scale out your pod (create new replicas), because of the CPU and RAM spikes. As new pod replicas boot, more requests arrive from the users, and more demands are being made towards the External Provider.
However, since the heavy load was the initial problem that caused the External Provider to stall, the problem is becoming even more prominent. Eventually, we end up having a non-healthy cluster, without a clear way to recover. The entire cluster will eventually recover once the users give up and stop trying to refresh their web pages.
When the crisis ends, the users are left with a bad experience. To make matters worse, this scenario will repeat itself whenever there is a spike in traffic.
All of this could have been avoided by putting a little extra care to Microservice C, which would instruct it to let the external provider take a short breath to recover in the cases where it would start to gradually become unresponsive.
Making A Microservice Fault Tolerant
Our cluster failed because of excessive resource usage while waiting for failed/delayed responses. I/O threads were piling up while microservices were waiting for the External Provide to reply. Let’s see how to remedy this using Quarkus.
In our case we need to instruct our microservice to do two things:
- Put a timeout in an HTTP request, so that the resources consumed while waiting for a response will be freed.
- Add Circuit Breaker — which means that after a certain threshold of failures, stop performing the HTTP requests towards the external provider for a certain amount of time.
Netflix’s blog post about network resiliency is an excellent source to allow a better understanding of those concepts and why they are important.
Constructing the initial project
Let’s imagine that you have already created a new project using https://code.quarkus.io/ and that you have added the REST Client and fault tolerance extensions
For this little experiment, we are going to use the https://restcountries.eu/ APIs and consider this as our External Provider.
Let’s construct an endpoint in Quarkus, and make it use a REST Client.
Here is our REST Client. For the sake of brevity, I chose not to parse the response to a model and leave it like a String so that we can focus on the issue at hand.
@RegisterRestClient(configKey = "CountriesClient")
public interface CountriesClient {
@GET
@Path("/rest/v2/all")
CompletionStage<String> getRestCountries();
}And here is the endpoint built to return its contents:
@Path("/countries")
public class RESTCountriesResource {
@Inject
@RestClient
ExampleRestClient restClient;
@GET
@Path("/")
@Produces(MediaType.APPLICATION_JSON)
public CompletionStage<String> hello() {
return this.restClient.getRestCountries();
}
}
Now the application.properties file should have only one entry:
CountriesRCountriesClient/mp-rest/url=https://restcountries.eu/We are ready to perform an mvn compile quarkus:dev , hit http://localhost:8080 and see that our endpoint returned the response of the RestCountries website, which is a list of all countries and their properties.
Now, let’s add a circuit breaker and a timeout pattern:
Go inside your application.properties and add the following lines:
CountriesClient/mp-rest/url=https://restcountries.eu/
#add the below lines
CountriesClient/mp-rest/connectTimeout=3000
CountriesClient/mp-rest/readTimeOut=3000
Also, add a circuit breaker to the endpoint of your rest client so that it looks like this:
@GET
@Path("/rest/v2/all")
@Asynchronous
@CircuitBreaker(failOn = TimeoutException.class, requestVolumeThreshold = 20, failureRatio = 0.5, delay = 30000)
public CompletionStage<String> getRestCountries();
The above changes instruct your REST client to do the following:
- Have a connect timeout and a read timeout of 3000 milliseconds
- If, during the course of 20 requests, we have a failure ratio of 0.5 (50%), then “open the circuit” (cut all subsequent connections) for 30 seconds. After 30 seconds, allow some requests to be made, and in the case where there is one successful operation, close the circuit completely, and allow all requests to be performed normally.
- The
Asynchronousannotation was added to instruct the Fault Tolerance library to treat this method as being asynchronous.
Mocking Failures and Testing Methodology
OK, so how can we simulate our failures? We can’t expect any external provider to be unavailable when we need it. So we should mock our responses and simulate a timeout ourselves.
Personally, I use Mockoon when it comes to mocking HTTP calls and simulating network issues. I have found it to be an excellent tool for performing those tasks.
In Mockoon, we can put the response that we obtained by the REST Countries endpoint that we got earlier, and change the URL of the REST client inside our Quarkus application to point to the localhost server of Mockoon
CountriesRCountriesClient/mp-rest/url=http://localhost:3000
Our setup in Mockoon should look like this:
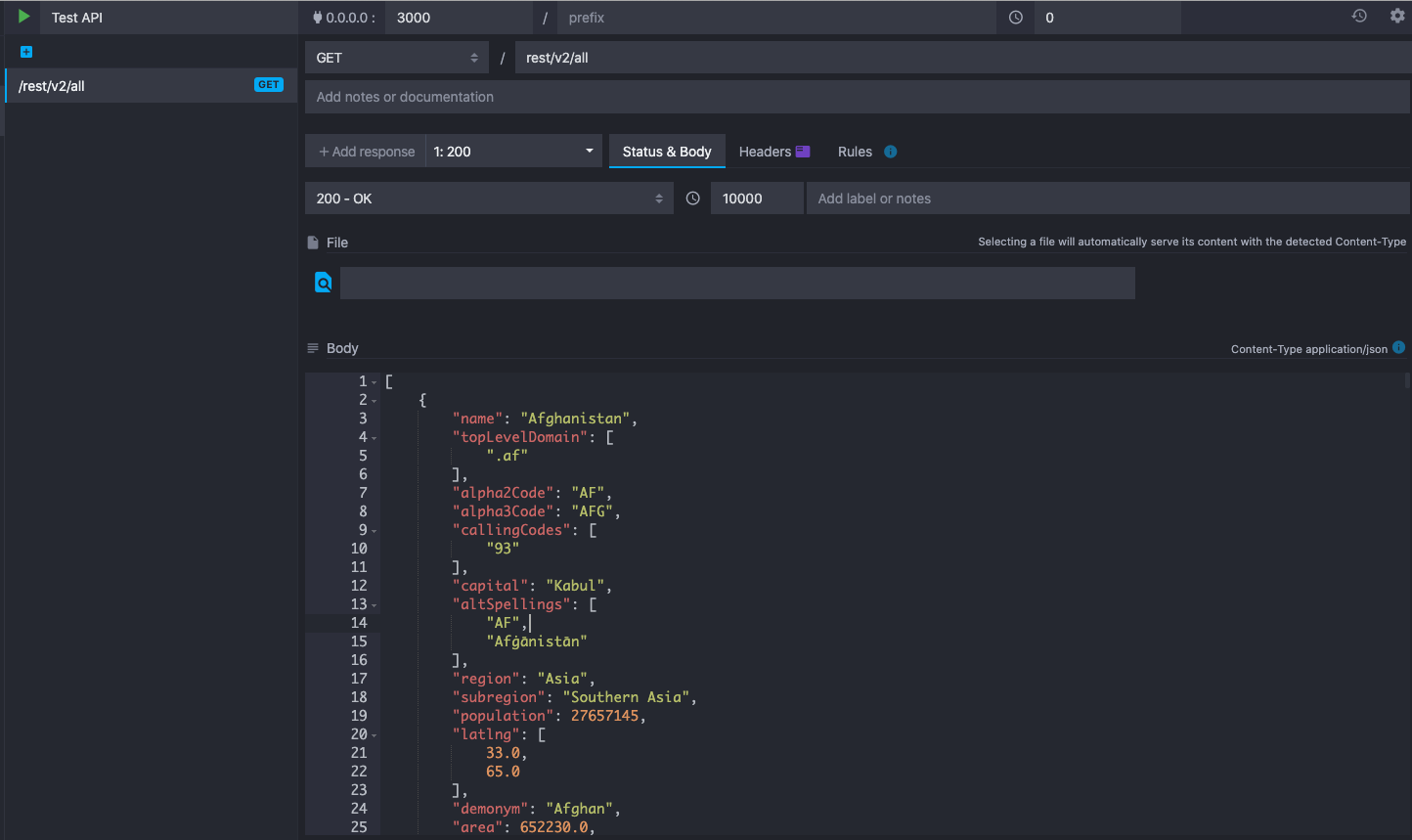
Notice that we have put a 10 seconds delay so that we can be sure that the timeout exception will be triggered.
Now start hitting your API a bunch of times and notice that after we make 21 failed attempts, the subsequent calls never reach Mockoon — they are cut by our application for the next 30 seconds.
Externalizing the MicroProfile Fault Tolerance configuration
The MicroProfile Specification location is not explicitly mentioned in the Quarkus documentation at the time of this writing (version 1.3.2.Final). Also, the methodology for configuring Fault Tolerance using application.properties is not mentioned in the Quarkus documentation.
There is, however, excellent official documentation by Eclipse, and I have found that Quarkus is 100% compliant with it.
According to the documentation, if we want to disable Circuit Breaker globally, we can put CircuitBreaker/enabled=false in our application.properties. Or, if we're going to be more specific about what we deactivate and whatnot, we can use <<org.mycompany.package>>.CountriesClient/CircuitBreaker=false and deactivate it only for this class.
There are tons of customizations we can do using the MicroProfile fault tolerance mechanics. I strongly recommend reading the whole document to better grasp the concepts and how those can be configured and applied to each use-case.
What did we achieve?
Let’s consider that our mocked scenario is a situation happening in a production environment. Having put a Timeout in combination with a Circuit Breaker mechanism would relieve our cluster from hundreds of I/O blocked threads. It would also stop our microservice from sending too many requests to any External Provider, thus allowing the latter to recover quicker from a failure.
Notes on Fault Tolerance Mechanics
Should we apply fault Tolerance Mechanics everywhere?
Absolutely not. As it happens with anything in Tech, overusing Fault Tolerance principles can have a detrimental effect on the health of a cluster.
Timeouts should be handled with care, and they are largely dependent on your business model. In the case of applications that tackle complex data structures or are B2B oriented, timeouts may be able to have larger values. For user-facing applications where speed is more important, timeouts can have lower values.
If we find ourselves being largely dependent on an external provider where we can’t have any influence regarding its implementation, we can use CircuitBreaker to avoid having an unhealthy cluster in the case where the external system is overloaded.
There are situations where a network transaction must be ensured at all costs. In those particular scenarios, a Retry mechanism can be added.
Regarding the use of the @Timeout annotation
Since the MicroProfile specification also provides an @Timeout() annotation, why didn't we use that and settled with the REST client's timeout in this example instead?
Whatever the implementation of the Fault Tolerance library we intend to use, we should keep in mind the following principles:
By applying an @Timeout above a method, what we can ensure is that the execution time of this method will not exceed a certain threshold. However, unless we have an excellent grasp of the underlying thread model of this method, we cannot be sure if all underlying threads will be canceled, too. This is evident mostly in asynchronous functions, where an I/O thread may be spawned to communicate with a database, or an external system via HTTP.
To be fair, the MicroProfile components seem to work very well together. More specifically, in my tests using Quarkus, I have seen that putting an @Timeout on top of the REST client's method seems to indeed cancel the underlying thread of the MicroProfile REST client). However, in some other cases, I have found that the @Timeout annotation can only stop the executing method and not the underlying I/O thread that may have been spawned. This is the case when using asynchronous SOAP requests using CXF, for example.
For this reason, I recommend applying the @Timeout annotation only if the framework used to perform a particular task does not provide it on its own.
I would make the same suggestion regardless of the Fault Tolerance implementation or the web framework used.
Other Fault Tolerance solutions
There are other solutions for Fault Tolerance in the Java world.
- Hystrix by Netflix was holding the crown for the most widely used Fault Tolerance implementation. However, it is now in maintenance mode and not actively developed
- Resilience4J seems to be the next best Fault Tolerance library in the Java world. It seems to work well with RxJava and the Reactor Framework. If you are using Spring Boot, it also provides annotations to facilitate the development and to avoid glue code.
Resiliense4J is very good, and I have successfully used it with Quarkus. However, I have found the MicroProfile specification to be far more comfortable and simpler to integrate with Quarkus — not to mention its tight integration with the latter.
What about other methodologies of Fault Tolerance?
Fault Tolerance implementations provide more features, like Retry Mechanisms and Fallbacks. This article tackled with only some basic features. Covering all Fault Tolerance features and best practices would require reading an entire book to explain patterns and common pitfalls.
Conclusion
I hope that during this small introduction to Fault Tolerance, the importance of putting this in the development pipeline becomes more critical.
Fault Tolerance was always essential, but in the era of microservices, it has become an indispensable tool for ensuring a Kubernetes cluster’s health. Fortunately, there are specifications like MicroProfile and Resilience4J that can provide those capabilities without too much hassle in the Java world.