Using Streams efficiently in NodeJS

I had the chance to work on a project involving some large files filled with data, and for many parts of the implementation, I had to use NodeJS for various reasons. One of the most common issues I was forced to tackle was how to download and parse a file containing a few millions of entries (around 500Mbytes) and then perform operations based on the content. Since the files were very big, I had to stream parts of the file in RAM and perform asynchronous operations in chunks.
I was stunned to see that so few resources existed on how to do this on the Internet. And many solutions that I found did not take into account large files and were incompatible with any back-pressuring model. I tried to use RxJS for my solutions, which proved to be a less-than-ideal tool for me to perform backpressure when using NodeJS’s read streams.
In this post, we will take a look at the problems I faced, and two approaches I followed to solve them. Only one of those approaches took me where I needed to go, and the other ones were wrong but also taught me many things, and this is why I will mention them, too.
Those are the issues we will tackle in this post
- How to download a very large file using streaming (the more popular but wrong way)
- How to download a very large file using streaming (the right way)
- Reading a large file using backpressure (the wrong way, using RxJS)
- Reading a large file using backpressure (the right way, using NodeJS streams)
Planning our little project
Imagine that there is a file that is uploaded into a server. We need to download this file, and for each line inside this file, we want to perform an asynchronous operation. Initially, this sounds simple, but this little project has some well-hidden issues (stemmed from the requirements), dangerous to the non-careful implementors.
We have the following requirements:
- We want to be as resource-efficient as possible.
- We want to be as fast as possible in processing.
- We need to parallelize as many operations as we can.
We are going to work with a large number of operations. Our imaginary file is going to have a size of 500.000K lines.
Well, this makes things a bit more complicated, doesn’t it? While working with large files and asynchronous operations, there are hidden dangers that we must anticipate.
- File size. We can’t just load the whole thing into RAM. We need to parse it line by line, and we need to do it in a streaming fashion. Luckily, file streams in NodeJS are excellent for those kinds of tasks.
- Asynchronicity. We know that NodeJS is asynchronous, and its i/o is a breeze, but what about concurrency? How can we efficiently manage parallel processes inside the code?
The approach that we will follow can be described in the following diagram.
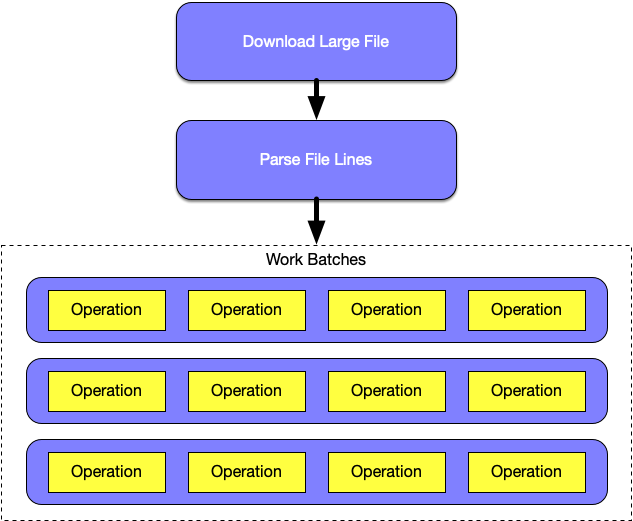
In short, what we intend to do is to first download the large file. Afterward, we will need to parse the file line-by-line. Each line represents a long asynchronous operation (3 seconds). Each line will be converted to an asynchronous operation, and those asynchronous operations will be grouped in groups with a certain concurrency applied.
Just to give an example — after processing of the file will have finished, 500.000 lines will have been split among 125.000 groups of 4 operations that run concurrently. The important thing is that only a small amount of those groups should exist in RAM.
We are going to examine two methods of performing the two major operations we need; Download a large file, and then parse it line by line and create batches of operations per line from it.
Downloading a large file using streams
At first, we will need to download the file. Since this is a large file, we need to download it in a streaming fashion — that means that we should write bytes to the disk as we receive it from the remote server.
We are going to use Axios to download the file. Axios has support for file downloading, so this should be easy. Or at least, it seemed easy at first.
Wrong way
In my searches on the Internet, I have come across answers such as this one:
But, this is totally false. It may seem correct because it will work… most of the time! And if you have a fast connection, the problems that this solution will bring you will remain hidden from you until you download a larger than usual file, or if you happen to use a less than ideal connection. The issue is that this method will not take into account the time it takes for the data to be streamed to the disk.
The function (response) is called when the connection is established and a stream has been opened, not when the file has been downloaded to the disk. This means, that we should modify the method in order to wait for the final byte to be written to the disk before we return our promise and let the execution flow resume.
Right way
This is what the correct version of the above looks like
If you use the later versions of NodeJS, you can shorten this implementation using this method below.
We have encapsulated the streaming part inside a Promise, and we have ensured that it won’t be resolved before the write stream has finished. This will make sure that promise will return when the file stream has been closed.
Creating asynchronous work batches
Since we have downloaded the large file we want, we now need to parse it line-by-line.
Reading a file and sending it to Rx (the wrong way)
We know that each line will need to be sent as an event to an RxJS Subject observable. For this reason, one could be inclined to use NodeJS' readline module, which reads a file line by line and sends each resulting line as an event to an Observable. Such an implementation would not require an extreme amount of effort, and could look like this:
This implementation could work, but when it comes to reading a very large file, it can bring even a powerful machine to a halt, and will kill the NodeJS process quickly after consuming some GB of RAM. Why? Let’s see the simple usage of this streaming method.
For the sake of simplicity, let’s imagine that the operation that we want to perform for a single batch of lines is a function returning a Promise after 3 seconds:
Considering this function, let’s use it in the context of a method that downloads the file, groups the lines into batches of 100 lines per batch, and runs three of those batches in parallel.
Let’s run the program. After 10 or more seconds, our small application crashes, with the following error:
FATAL ERROR: CALL_AND_RETRY_LAST Allocation failed - JavaScript heap out of memory 1: node::Abort() [/usr/bin/node] 2: 0xe2c5fc [/usr/bin/node] 3: v8::Utils::ReportApiFailure(char const*, char const*) [/usr/bin/node] 4: v8::internal::V8::FatalProcessOutOfMemory(char const*, bool) [/usr/bin/node] 5: v8::internal::Factory::NewRawTwoByteString(int, v8::internal::PretenureFlag) [/usr/bin/node] 6: v8::internal::Runtime_SparseJoinWithSeparator(int, v8::internal::Object**, v8::internal::Isolate*) [/usr/bin/node] 7: 0x3629ef50961bSo what happened? This can be explained at what’s happening under the hood. Consider the following diagram:
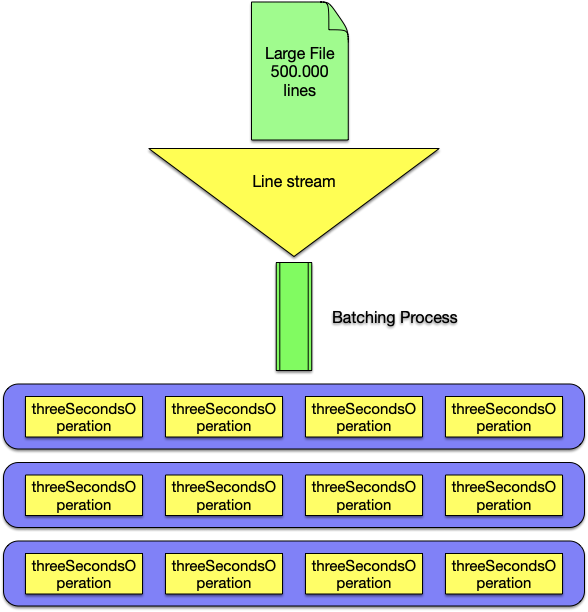
Lack of back-pressuring, that’s what happened!
One could very easily assume that since we are using RxJS pipe along with bufferCount and mergeMap, this would suffice to have a back-pressure mechanism in place because Rx will not start the next batch unless one of the 3 previous batches have been completed (note the concurrency 3 in the example). However, this kind of back-pressure only happens in the "Rx Land" - NodeJS' input stream doesn't know that there is a back-pressure mechanism in place - in other words, Node's stream modules have no way of being notified of RxJS's concurrency or backpressure model.
This results in Node’s stream (which is the underlying module that readline uses) to continuously read new lines and send them to the RxJS's stream, which in turn it will pile them up since only three batches can be run at a time. The lines read by the stream will continue to pile up until the process runs out of heap memory.
Reading a file, applying back-pressure using TransformStreams (the right way)
What we need is to put a back-pressure mechanism when reading the data, using Node’s tools, i.e., Transform Streams. To do this, we will need to refactor our code to perform the following actions:
- Setup a file read stream using
fs - Pipe the read stream to the
split2module which is used to take an input stream (raw bytes) and output them line-by-line - Pipe the resulting stream once more to a
through2transform stream. through2 is a library that wraps NodeJS transform streams in a way where it allows the developer to easily call a callback when it finishes processing the current chunk from a stream. A Node stream will not send more data down the pipeline if thecallbackhas not been called. - Get rid of RxJS for this business case, completely.
Rx is an extremely good framework, but when it comes to NodeJS, I find it severely lacking when it comes to combining Rx streams with Node’s streams. And whatever 3rd party implementations I have found, they don’t tackle at all back-pressuring with Node’s streams.
Let’s now consider this function:
In the above example, the promiseThunk is a function that generates a Promise, and receives a string array as an argument. This string array is the string batch we have processed. The concept behind this method is slightly more complicated than the one where we used Rx, but at its core, it's really simple; We create a new read stream and we are managing the backpressure via the through2.
We are calling the callback of the transform stream only when we have called our promiseThunk function, and gotten the result. This will pause the stream processing until we call the callback() again. When the read stream is closed, we may have some leftovers inside the buffer so we need to call promiseThunk once more, before we can safely say that our processing has finished. This is why we encapsulate all this logic inside an outer Promise, to better handle when our Promise is going to be resolved or rejected.
Now let’s modify our previous code and call this method:
Let’s run the code once more. Notice that threeSecondsOperation is now called properly, after the previous batch of 100 lines has completed processing.
What about concurrency? The RxJS solution, although flawed, was cleaner and easier when it came to load distribution and concurrency. In this solution, what we can do is to modify threeSecondsOperation. Inside it, we can create 4 promises from the lines passed as an argument to and return the result of a Promise.all().
Everything runs smoothly and our memory footprint is really low!
Conclusion
For me, trying to figure out the best way to tackle those issues has uncovered a world of truths, which seems to be hidden from plain sight. After solving my problems, there are some observations I made that I feel I should share.
First of all, it seems that using Rx makes less sense when working with NodeJS (yes, I do not consider that one uses NodeJS when using Angular for the frontend), than when working with Java for my use cases. In Java, I have solved the exact same issue with RxJava, and I applied back-pressure.
A similar implementation of a file processor in RxJava with proper back-pressure applied would look like this
The difference between RxJs and RxJava stems from how both languages handle asynchronicity. RxJava has a predictable threading model, and even when running on a single thread, its asynchronicity is deterministic. For example, the BufferedReader in Java runs on the same thread and doesn’t force us to subscribe to events like Node does - thus allowing RxJava to wrap it nicely and apply backpressure to it. In Javascript/Typescript, however, we are forced to do everything asynchronously and subscribe to a stream’s events.
On the other hand, we didn’t need any 3rd party streaming framework to do what we needed when using NodeJS, so, I guess that’s one huge plus in favour of Node.
Thank you for taking the time to read this article. I would be very interested to see alternative implementations.